- Published on
A Simplified Approach to Backtesting Trading Strategies
This blog post focuses on a novel way to backtest trading strategies, aiming to reduce the chances of backtest overfitting. The technique uses statistical characteristics from historical data to generate synthetic datasets for testing.
The Issue of Backtest Overfitting
In the field of investment strategies, overfitting happens when a strategy performs well on historical data but poorly on new, unseen data. One common way to avoid this problem is by calibrating trading rules based on the stochastic process generating the data, rather than purely relying on historical simulations.
Understanding the Investment Strategy
Let's consider an investment strategy which invests in multiple opportunities. The value of each opportunity at any given time can be calculated as , and the profit/loss after transactions is represented as .
The strategy uses a standard trading rule for exiting an opportunity when either of the following conditions are met:
- The profit crosses a pre-defined threshold .
- The loss crosses a pre-defined threshold .
The trading rule is defined by these thresholds .
The goal is to find the optimal set of these thresholds, often denoted as , that maximizes the Sharpe ratio, , defined as:
Defining Overfitting in Trading Rules
A trading rule is considered overfit if it is expected to perform worse than the median of alternative rules in out-of-sample data.
Algorithm to Find Optimal Trading Rules
The algorithm for finding optimal trading rules involves these steps:
- Estimate the parameters .
The rest of the algorithm will be discussed in the next section.
These functionalities are available in both Python and Julia in the RiskLabAI library.
Using Synthetic Backtesting for Optimal Trading Rules in RiskLabAI
The RiskLabAI library offers a function for synthetic backtesting, which is useful for developing optimal trading rules without overfitting to historical data. This function can be implemented in both Python and Julia.
def synthetic_back_testing(
forecast: float,
half_life: float,
sigma: float,
n_iteration: int = 100000,
maximum_holding_period: int = 100,
profit_taking_range: np.ndarray = np.linspace(0.5, 10, 20),
stop_loss_range: np.ndarray = np.linspace(0.5, 10, 20),
seed: int = 0
) -> list[tuple[float, float, float, float, float]]:
rho = 2 ** (-1. / half_life) # compute ρ coefficient from half-life
back_test = []
for profit_taking, stop_loss in product(profit_taking_range, stop_loss_range):
stop_prices = []
for iteration in range(n_iteration):
price, holding_period = seed, 0 # initial price
while True:
price = (1 - rho) * forecast + rho * price + sigma * gauss(0, 1) # update price using O_U process
gain = price - seed # compute gain
holding_period += 1
if gain > profit_taking or gain < -stop_loss or holding_period > maximum_holding_period: # check stop condition
stop_prices.append(gain)
break
mean, std = np.mean(stop_prices), np.std(stop_prices) # compute mean and std of samples
back_test.append((profit_taking, stop_loss, mean, std, mean / std)) # add mean, std, and Sharpe ratio to backTest data
return back_test
Functionality
The function operates on parameters like forecast prices, half-life of the model, and standard deviation. It then runs multiple iterations to identify optimal trading rules based on a combination of profit-taking and stop-loss ranges. The aim is to maximize the Sharpe ratio.
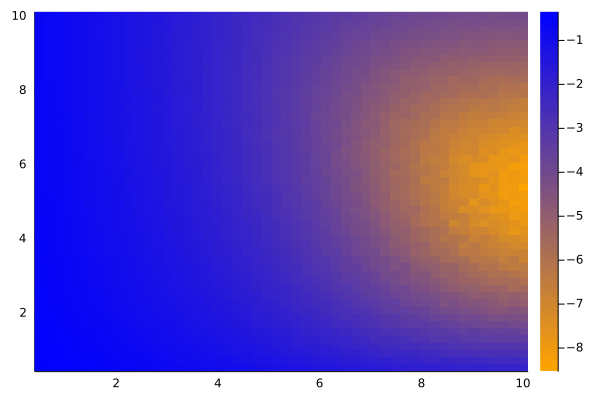
Experimental Results
The experiments suggest that there is a unique optimal trading rule that can be determined for a financial instrument whose price follows a discrete Ornstein-Uhlenbeck (O-U) process.
References
- De Prado, M. L. (2018). Advances in financial machine learning. John Wiley & Sons.
- De Prado, M. M. L. (2020). Machine learning for asset managers. Cambridge University Press.