- Published on
Distance Metrics
- Authors

- Name
- Tails Azimuth
Table of Contents
- Correlation-Based Metrics
- Information Theory Concepts
- Information-Based Metrics
- Practical Implementation
- Discretization (Binning)
- Distance Between Partitions
- Experimental Results
- Implementation: Information-Theoretic Metrics
- Variation of Information (VI)
- Mutual Information (MI)
- Optimal Binning
- Correlation-Based Distances
- API reference
Distance Metrics
This chapter argues that Pearson's correlation is a limited measure of codependence because it is not a true metric, it only captures linear relationships, and it is sensitive to outliers. It introduces concepts from information theory, primarily entropy, as a more robust foundation for measuring distance and similarity, which is critical for many machine learning algorithms.
Correlation-Based Metrics
While correlation () itself is not a distance metric, it can be used to create one. A true metric must satisfy non-negativity and the triangle inequality.
- For Long-Only Portfolios: This metric treats negative correlations as highly distant, which is useful for diversification.
- For Long-Short Portfolios: This metric (a true metric on the quotient) treats highly positive and highly negative correlations as "close" (i.e., strong relationships).
The text proves these are true metrics by showing they are linear multiples of the Euclidean distance between the z-standardized vectors.
Information Theory Concepts
To overcome the limitations of correlation (linearity, outliers), the chapter introduces entropy-based measures.
- Shannon's Entropy : Measures the amount of uncertainty associated with a random variable . It is maximized when all outcomes are equally probable.
- Joint Entropy : Measures the total uncertainty of two variables and .
- Conditional Entropy : Measures the remaining uncertainty in after is known.
- Kullback-Leibler (KL) Divergence : Measures how much a probability distribution diverges from a reference distribution . It is not a metric because it is not symmetric ().
- Cross-Entropy : A popular loss function for classification, it measures the uncertainty of using an incorrect distribution .
Information-Based Metrics
From these concepts, we can derive true distance metrics.
Mutual Information (MI):
- Concept: Measures the "information gain" about from knowing . It is a generalized, non-linear measure of correlation.
- Equation:
- Property: is not a metric because it fails the triangle inequality.
Variation of Information (VI):
- Concept: This is the chapter's preferred true metric based on information theory. It measures the total uncertainty remaining in and after accounting for the information they share.
- Equation:
- Normalized VI (Bounded [0,1]): A normalized version useful for comparing distances.
Practical Implementation
Discretization (Binning)
Entropy formulas require discrete variables. To use them on continuous data (like returns), the data must be binned. The choice of binning is critical. The chapter provides an optimal binning formula for joint entropy:
- Optimal Bins:
Distance Between Partitions
The VI metric can also be used to measure the distance between two different clusterings (partitions), and , of the same dataset.
- Equation:
Experimental Results
A test on a nonlinear relationship () shows that correlation fails (), while Mutual Information and Variation of Information successfully detect the strong codependence.
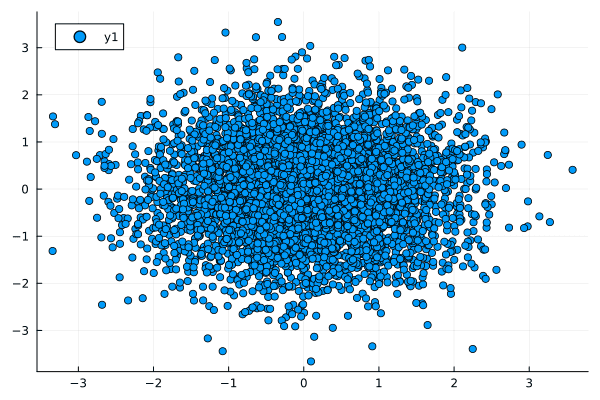
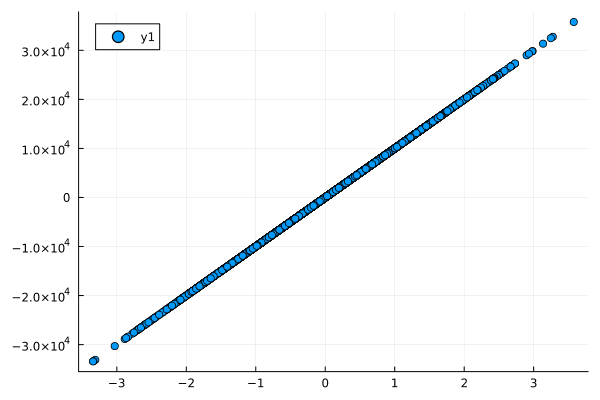
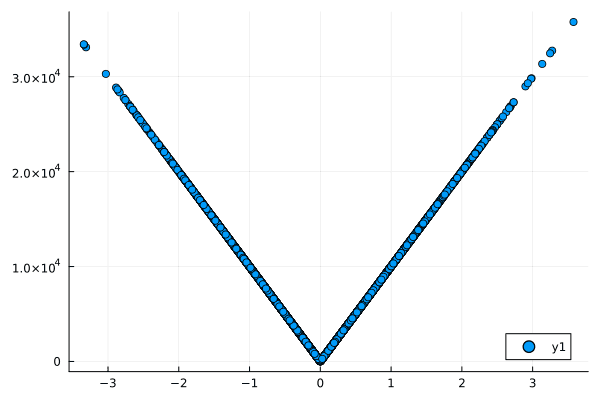
Implementation: Information-Theoretic Metrics
To measure the dependence between features, standard linear correlation is often insufficient as it fails to capture non-linear relationships. In the data.distance.distance_metric module, we implement several information-theoretic metrics.
Variation of Information (VI)
The Variation of Information (VI) provides a true metric on the space of partitions. VI(X, Y) = 0 when X and Y are identical, and VI(X, Y) = H(X, Y) when they are independent. We provide a normalized version (by H(X, Y)) to bound the metric between [0, 1].
Mutual Information (MI)
We also implement Mutual Information (MI), which measures the information that X and Y share. We provide a normalized version, MI_norm = MI(X, Y) / min(H(X), H(Y)), which is bounded between [0, 1].
Optimal Binning
Both VI and MI require discretizing the continuous variables. A poor choice of bins can lead to misleading results. We implement a function to calculate the optimal number of bins based on the number of observations and their correlation.
Correlation-Based Distances
Finally, for use in clustering algorithms, we provide functions to convert a correlation matrix into a true distance matrix.
Supported metrics include 'angular' () and 'absolute_angular' ().
API reference
RiskLabAI implements these in Python and Julia (signatures auto-generated from the package source):
| Python | Julia |
|---|---|
| |
| |
| |
| |
| |