- Published on
Ensemble Methods
Ensemble Methods
This chapter explains why ensemble methods are effective and how to avoid common errors when applying them to finance. Ensembles combine multiple "weak learners" to create a single "strong learner" that performs better by reducing bias and/or variance.
The Three Sources of Errors
All ML models suffer from three types of errors. The goal is to minimize their sum.
- Bias: Error from unrealistic assumptions (causes underfitting).
- Variance: Error from sensitivity to small changes in the training data (causes overfitting).
- Noise: Irreducible error () from the data itself.
The Mean-Squared Error (MSE) of an estimator can be decomposed as:
Bootstrap Aggregation (Bagging)
Bagging is an ensemble method designed primarily to reduce variance (overfitting).
Process:
- Generate training datasets by random sampling with replacement (bootstrapping).
- Fit independent estimators, one on each dataset (can be done in parallel).
- The final forecast is the average (for regression) or majority vote (for classification).
Variance Reduction: The variance of the bagged forecast is a function of the average variance () and average correlation () of the individual estimators:
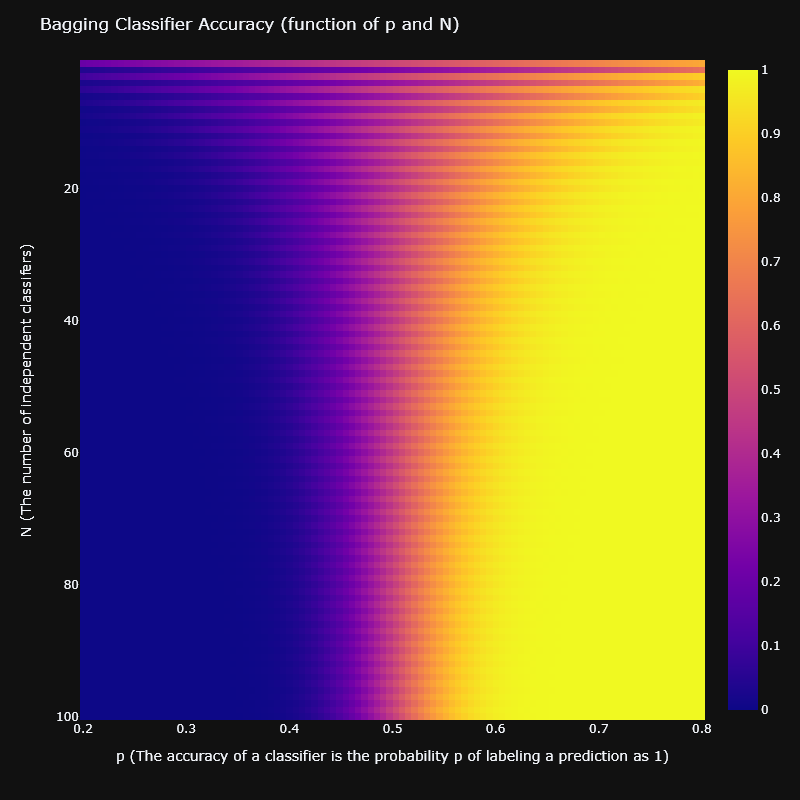
Key Insight: Bagging is only effective if the estimators are not perfectly correlated (). As (the number of estimators) increases, the variance is reduced, converging to .
Improved Accuracy: Bagging can improve accuracy if the individual classifiers are better than random chance (, where is the number of classes). The probability of a correct majority vote (where ) is:

Random Forest (RF)
Random Forest is a specific type of bagging that uses decision trees as the weak learners. It is designed to combat the high variance (overfitting) tendency of individual trees.
- Key Difference from Bagging: RF introduces a second level of randomness. At each node split, it only evaluates a random subsample of the features.
- Purpose: This further decorrelates the individual trees (lowers ), leading to a more significant reduction in variance.
- Problem in Finance: RF still suffers from the observation redundancy problem. If samples are redundant, RF will build many identical, overfit trees ().
- Solutions:
- Use
BaggingClassifieron aDecisionTreeClassifierand setmax_samplesto the average uniqueness of the labels. - Modify the RF algorithm to use the Sequential Bootstrap (from Ch. 4) instead of standard bootstrapping.
- Use
Boosting
Boosting is an ensemble method designed to reduce both bias (underfitting) and variance.
- Process:
- Estimators are fit sequentially.
- At each step, the algorithm increases the sample weights of misclassified observations.
- This forces subsequent estimators to focus on the "hard" examples that were previously wrong.
- The final forecast is a weighted average of the estimators, giving more weight to those with higher accuracy.
Bagging vs. Boosting in Finance
- Bagging: Addresses overfitting (variance). It is parallelizable.
- Boosting: Addresses underfitting (bias). It is sequential.
Conclusion: In finance, the signal-to-noise ratio is very low, making overfitting the primary concern. Therefore, bagging is generally preferable to boosting for financial applications.
Bagging for Scalability
Bagging can also be used as a practical tool to apply non-scalable algorithms (like SVMs) to very large datasets.
- Method: Use
BaggingClassifierwith a base estimator (e.g.,SVM) but force an early stopping condition (like setting a lowmax_iter). - Result: This transforms one large, slow, sequential task into many small, fast, parallel tasks. The bagging process compensates for the high variance introduced by the early stopping.
Weighted Voting in Bagging Ensembles
While standard bagging (like Random Forest) uses a simple majority vote (uniform weighting), we can also explore weighted voting schemes. The goal is to give more influence to estimators that are more accurate or less correlated. In our RiskLabAI.ensemble.empirical_bagging_accuracy module, we provide a class to analyze these schemes, as described in Chapter 6, Section 6.5.
Methodology
We evaluate three weighting schemes based on the in-sample accuracy () of each individual estimator:
- Uniform: . This is the standard bagging vote.
- Accuracy-weighted: . Gives more weight to trees that had higher in-sample accuracy.
- Variance-weighted: . Gives more weight to trees with accuracy not close to 1, as implies zero variance (overfit) and implies maximum variance.
Implementation
- The
BaggingClassifierAccuracyclass implements this analysis. It fits aBaggingClassifierand provides methods tocalculate_c_i(in-sample accuracy for each tree) andcalculate_weightsfor all three schemes. Thepredictmethod can then generate predictions using a specified weighting scheme, andevaluate_all_schemescompares their out-of-sample performance. - The module also includes
calculate_bootstrap_accuracy, which estimates the mean and standard deviation of a model's accuracy by bootstrapping the test set. This helps assess the stability of the performance metric itself.
API reference
RiskLabAI implements these in Python and Julia (signatures auto-generated from the package source):
| Python | Julia |
|---|---|
| |
| |
| |
| |