Cross-Validation in Finance
This chapter explains why standard cross-validation (CV) methods, like k-fold, fail in finance and lead to overfit models with false results. The core issue is that financial data is not IID (Independent and Identically Distributed), which causes "leakage" between the training and testing sets.
Why k-fold CV Fails in Finance
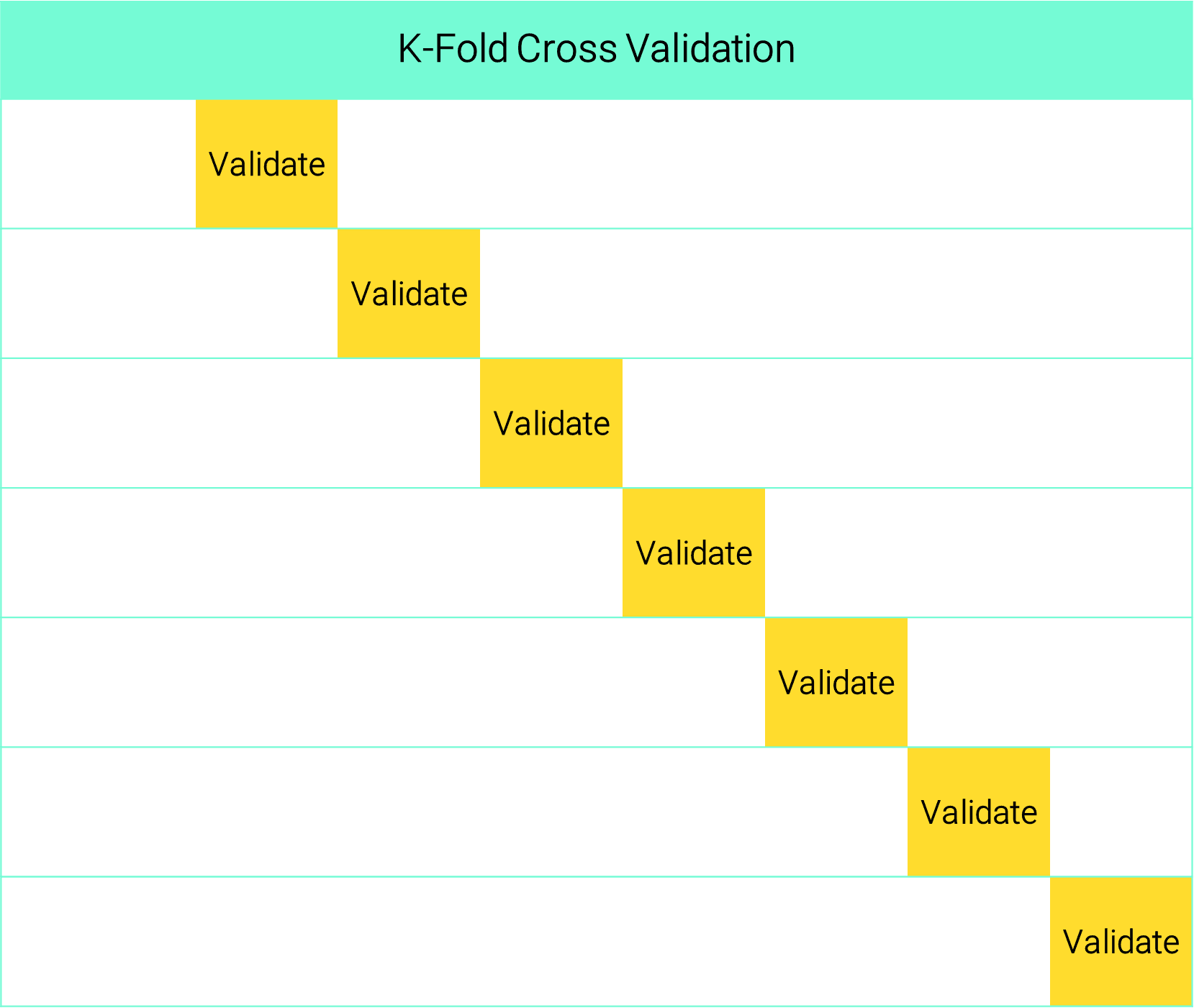
Standard k-fold CV works by partitioning data into k subsets, then training on k−1 sets and testing on the 1 set that was held out. This process assumes that all observations are independent.
This assumption is false in finance due to:
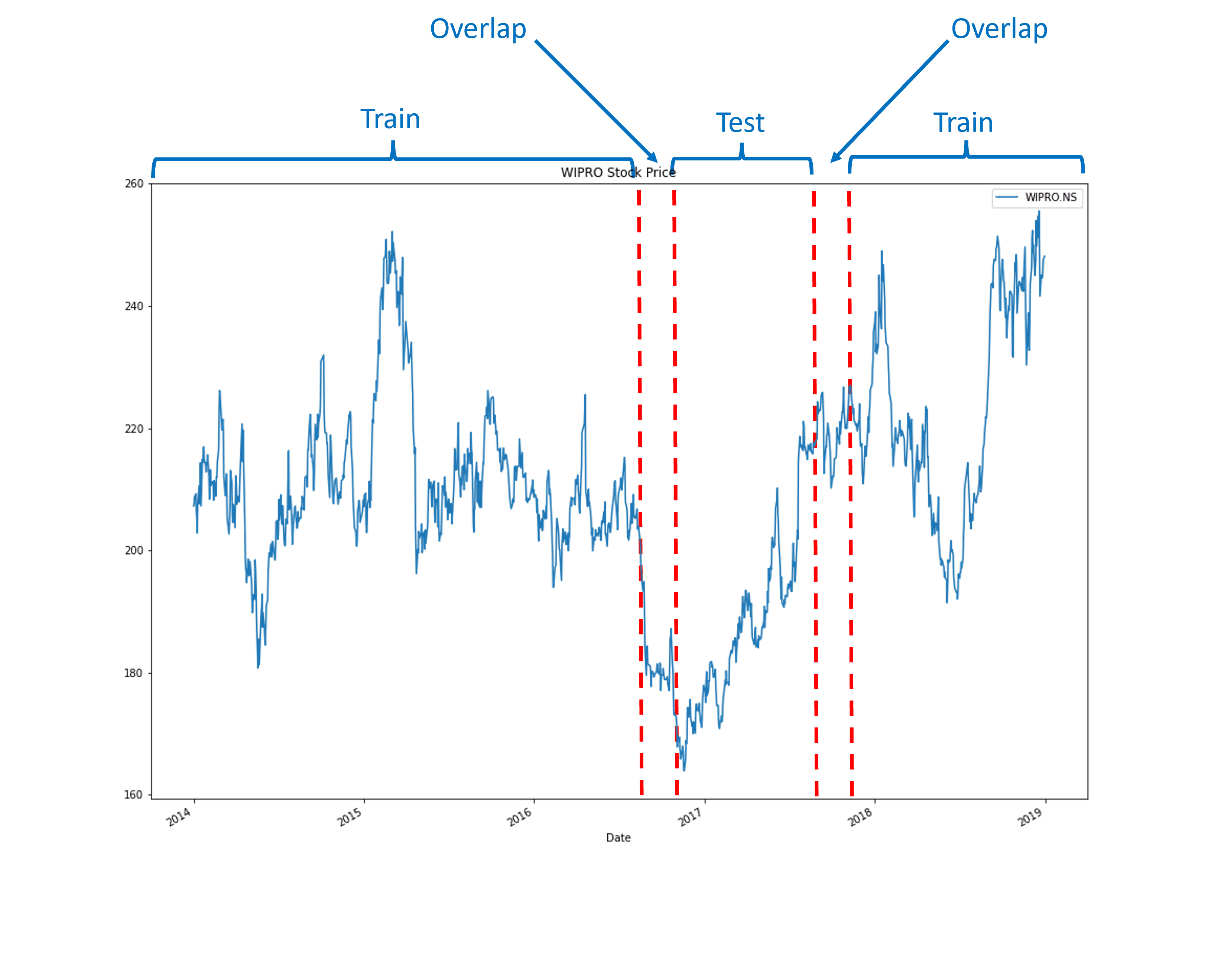
- Serial Correlation: Features are correlated over time (Xt≈Xt+1).
- Overlapping Labels: Labels (outcomes) are derived from overlapping time periods, as discussed in Chapter 4 (Yt≈Yt+1).
This creates information leakage. When the training set contains observations that are not truly independent of the testing set, the model isn't learning a general pattern. It's effectively "cheating" by training on data that is contaminated with information from the test set. This leads to falsely high-performance scores and models that fail in live trading.
The Solution: Purged k-fold CV
To fix this, the author proposes a new "Purged k-fold" method that prevents leakage by actively removing contaminated observations. This involves two steps:
1. Purging
This is the main step. Before training a model, we "purge" (delete) any observations from the training set whose labels were derived from a time period that overlaps with the time period of any label in the testing set.
This ensures that the model cannot train on any observation that shares information with the test set, even if the features themselves are from different times.
2. Embargo
Purging alone may not be enough if features are also serially correlated (e.g., ARMA processes). An "embargo" is an additional safety measure.
After a test set, we also remove a small number of training observations that immediately follow it. This creates a small buffer (e.g., 1% of the total data) to ensure that the model doesn't train on data that is still "ringing" with the effects of the test period.
By combining purging and embargoing, the "Purged k-fold" CV method creates truly independent training and testing sets, providing a realistic assessment of a model's generalization error and preventing false discoveries.
API reference
RiskLabAI implements these in Python and Julia (signatures auto-generated from the package source):
| Python | Julia |
|---|
class KFold(CrossValidator):
| struct KFoldCV
n_splits::Int
shuffle::Bool
rng::AbstractRNG
end
KFoldCV(n_splits::Integer; shuffle::Bool = false, random_seed = nothing) = KFoldCV(
n_splits,
shuffle,
random_seed === nothing ? default_rng() : MersenneTwister(random_seed),
)
|
class PurgedKFold(CrossValidator):
| struct PurgedKFoldCV
n_splits::Int
event_starts::Vector
event_ends::Vector
embargo::Float64
end
PurgedKFoldCV(
n_splits::Integer,
event_starts::AbstractVector,
event_ends::AbstractVector;
embargo::Real = 0.0,
) = PurgedKFoldCV(n_splits, collect(event_starts), collect(event_ends), Float64(embargo))
|
class CombinatorialPurged(PurgedKFold):
| struct CombinatorialPurgedCV
n_splits::Int
n_test_groups::Int
event_starts::Vector
event_ends::Vector
embargo::Float64
end
function CombinatorialPurgedCV(
n_splits::Integer,
n_test_groups::Integer,
event_starts::AbstractVector,
event_ends::AbstractVector;
embargo::Real = 0.0,
)
|
class WalkForward(KFold):
| struct WalkForwardCV
n_splits::Int
max_train_size::Union{Nothing,Int}
gap::Int
end
WalkForwardCV(n_splits::Integer; max_train_size = nothing, gap::Integer = 0) =
|
def bagging_classifier_accuracy(N: int, p: float) -> float:
| function bagging_classifier_accuracy(N::Integer, p::Real)
|
class BaggingClassifierAccuracy:
"""
Evaluates a bagging classifier's accuracy using different
weighting schemes based on decision tree c_i scores.
Methods:
- fit: Fits the bagging classifier.
- calculate_c_i: Calculates the c_i score for each tree.
- calculate_weights: Computes weights (uniform, c_i, 1-c_i^2).
- predict: Predicts class labels using specified weights.
- evaluate_all_schemes: Gets accuracy for all weighting schemes.
"""
def __init__(
self,
n_estimators: int = 1000,
max_samples: int = 100,
max_features: float = 1.0,
random_state: Optional[int] = None,
):
| function fit_bagging(
x::AbstractMatrix{<:Real},
y::AbstractVector;
n_estimators::Integer = 1000,
max_samples::Integer = 100,
max_features::Integer = 1,
random_state = nothing,
)
|
def calculate_bootstrap_accuracy(
clf: BaggingClassifier, X: pd.DataFrame, y: pd.Series, n_bootstraps: int = 1000
) -> tuple[np.ndarray, float, float]:
| function calculate_bootstrap_accuracy(
trees,
classes,
x::AbstractMatrix{<:Real},
y::AbstractVector;
weights::AbstractVector{<:Real} = fill(1.0 / length(trees), length(trees)),
n_bootstraps::Integer = 1000,
random_state = nothing,
)
|
def backtest_predictions(
self,
estimator: Union[Estimator, dict[str, Estimator]],
data: Union[pd.DataFrame, dict[str, pd.DataFrame]],
labels: Union[pd.Series, dict[str, pd.Series]],
sample_weights: Optional[Union[np.ndarray, dict[str, np.ndarray]]] = None,
predict_probability: bool = False,
n_jobs: int = 1,
) -> Union[dict[str, np.ndarray], dict[str, dict[str, np.ndarray]]]:
| function cross_val_score(
cv,
x::AbstractMatrix{<:Real},
y::AbstractVector;
n_trees::Integer = 100,
n_subfeatures::Integer = -1,
max_depth::Integer = -1,
scoring::Symbol = :accuracy,
random_state::Integer = 0,
)
|
Full source: Python · Julia